The Genomic Evidence for Common Descent: 2. Gene similarity and the consonance of evolutionary trees
Special creationists, well aware that the genomics evidence provides compelling evidence for common descent have attempted to explain this away by appealing to common design. This argument fails to recognise that given the redundancy of the genetic code, there are hundreds of billions of ways to code for exactly the same short protein: the potential genomic coding space is unimaginably large.
Common descent would predict that the coding sequences for a gene common to all life would cluster in a group, with closely related organisms differing by only a few mutations, while organisms that are distantly related would have had time since they last shared a common ancestor for many mutations to build up. Conversely, if special creation was true, we would not expect to see the gene sequences cluster in this way: in fact, there is enough room in the 'gene space' for each species to have its own coding sequence with a considerable amount of space around each gene, thus neatly refuting common descent.
What we see is a remarkable consonance between molecular and morphological phylogenetic trees. Common descent is the only rational explanation for this. Here's why:
The genetic code is a system in which the information required to code for proteins (complex molecules that have many functions including structural, signalling, regulatory, and enzymatic roles) is encoded in DNA and RNA. Proteins are complex polymers of simpler molecules known as amino acids. There are 20 standard amino acids in the human body, and each is encoded by one or more codons, consecutive sequences of three nucleotides:
 |
| A series of codons in part of an RNA molecule. Each codon consists of three nucleotides, usually representing a single amino acid. (Source: Wikipedia) |
Due to the redundancy of the genetic code which has 64 possible codons to code for 20 standard amino acids and stop codons, there is more than one way to encode for each codon. On average, this amounts to approximately three codons per amino acid.
This means that for a protein such as cytochrome c (involved in cellular respiration and programmed cell death) which is around 104 amino acids long, there are around 3^104 or around 4.1x10^49 possible ways to encode for the same cytochrome c protein. Another consequence of the redundant genetic code is that it is possible for each codon to tolerate point mutations without necessarily changing the amino acid for which it encodes. This can be readily seen in leucine, valine, serene, proline, threonine, alanine, and glycine, where any change in the third codon will not result in a change in amino acid.
The significance of this is readily seen when we look at what common descent would predict we would see in the cytochrome c gene of all life forms in which this gene appears. If all life shares a common ancestor, then we would expect to see that this vital gene would be highly conserved, with the amino acids sequence not varying by much at all, apart from the neutral changes mentioned above. Furthermore, any species which share a recent common ancestor would have cytochrome c genes that differ by only a few point mutations whereas those with a remote common ancestor would differ by more point mutations, as far more time has elapsed in the time since their ancestors separated.

In fact, the situation is more complex than this as cytochrome c has functional redundancy in its amino acid sequence. This means that cytochrome c can tolerate changes in its amino acid sequence and still perform the same biological function. In fact, only around one third of its amino acid sequence cannot be changed. When we factor in both coding and protein redundancy, the total number of ways in which one can code for a functional cytochrome c gene is around 2.3 x 10^93 possible genes.
Finally, there is no reason that a particular animal needs a particular cytochrome c molecule. Genetic experiments have been done in which cytochrome c proteins from humans [1], fish, birds, insects, and mammals [2-3] functioned perfectly well in yeast cells which had their cytochrome c genes removed, showing that there is no biological reason why closely related species need to have similar or identical cytochrome c proteins. Common descent would be falsified if the cytochrome c sequences for closely related animals such as humans and chimps differed considerably.
What we see is in complete agreement with common descent. The cytochrome c amino acid sequences for humans and chimpanzees are identical. The cytochrome c genes for these primates differs by only four nucleotides out of 104, a difference of a little over 1%. Conversely, the amino acid sequence for the yeast Candida differs from humans by 51 amino acids. This has been appreciated for decades. Legendary geneticist Theodosius Dobzhansky, one of the scientists responsible for creating the modern synthetic theory of evolution noted:
The cytochrome C of different orders of mammals and birds differ in 2 to 17 amino acids, classes of vertebrates in 7 to 38, and vertebrates and insects in 23 to 41; and animals differ from yeasts and molds in 56 to 72 amino acids.
and observed that the multiple lines of evidence of this nature "make sense in the light of evolution: they are nonsense otherwise." [4]
Dobzhansky was needless to say correct. It is impossible to credibly explain why when we look at the coding sequences and amino acids for scores of proteins shared across all forms of life from yeast to mouse to man, we see that closely related species differ by fewer amino acids or nucleotides than more distantly related sequences, or why when we plot this information, the phylogenetic tree agrees remarkably well with the consensus tree. Common descent explains this perfectly. Special creation has no explanation other than to claim that 'God did it', which leaves open the question of why God is creating life in such a way as to simulate common descent right down to the genomic level.
The differences are not related to differing functional needs
Creationists attempts to explain away this evidence are unconvincing. The Christadelphian John Watts has argued that:
These enzymes have ‘active centres’ that accomplish this remarkable feat; but in order to have the requisite activity, these centres are very restricted in their chemical structure. Thus an enzyme in a snail performing the same reaction found in a dog will almost certainly have a very similar active centre, and we may suspect that the differences are more to do with optimising the performance of the molecule for activity in snail and dog than with chance. [5]
Watts has missed the point completely. Coding redundancy means there are many ways in which a protein of a given length can be encoded. As we saw earlier, for cytochrome c, there are approximately 3^104 or 4.1 x 10^49 possible ways to encode for the same 104 amino acid sequence. There is no reason to favour one possible coding sequence over another, but in fact when we look at the coding sequences for cytochrome C in life, we find them clustering together in a way consistent with common descent. Any argument that each species needs its particular unique cytochrome C is undermined by the fact that human [6] and rat [7] cytochrome C have been inserted into yeast cells and functioned adequately.
His argument that enzymes are very restricted in their chemical structure is not always true. Again, with respect to cytochrome c, we now that only 33% of the amino acids are necessary for it to function. In other words, most of the amino acids can be replaced by functionally similar amino acids. This means that a functional cytochrome C enzyme does not need to be specified by the same 104 amino acids. Given the fact that we now have amino acid as well as coding redundancy, the potential coding space for a functioning cytochrome c enzyme is considerably larger than 3^104 possible genes.[8] The number has been calculated [9] as being around 2x10^93. Despite this unimaginably large potential coding space, the cytochrome c sequences of humans and chimpanzees are identical. Giving humans and chimpanzees completely different cytochrome C sequences would have been trivial for an intelligent designer, and would have been difficult to reconcile with common descent. One is entirely justified in the face of this evidence to conclude that common descent is the most reasonable explanation for the molecular genetics evidence.
The consonance between molecular and morphological phylogenetic trees
If common descent is true, then we would expect both the evolutionary family tree constructed using anatomical data and molecular data to be consonant. Both are after all instantiations of the underlying true family tree of life. Conversely, if both trees were hopelessly discordant, common descent would be effectively falsified. What we see however is a remarkable agreement between them. As Douglas Theobald points out when commenting on the remarkable consonance between molecular and morphological phylogenetic trees:
So, how well do phylogenetic trees from morphological studies match the trees made from independent molecular studies? There are over 10^38 different possible ways to arrange the 30 major taxa represented in Figure 1 into a phylogenetic tree... In spite of these odds, the relationships given in Figure 1, as determined from morphological characters, are completely congruent with the relationships determined independently from cytochrome c molecular studies...Speaking quantitatively, independent morphological and molecular measurements such as these have determined the standard phylogenetic tree, as shown in Figure 1, to better than 38 decimal places. [10]
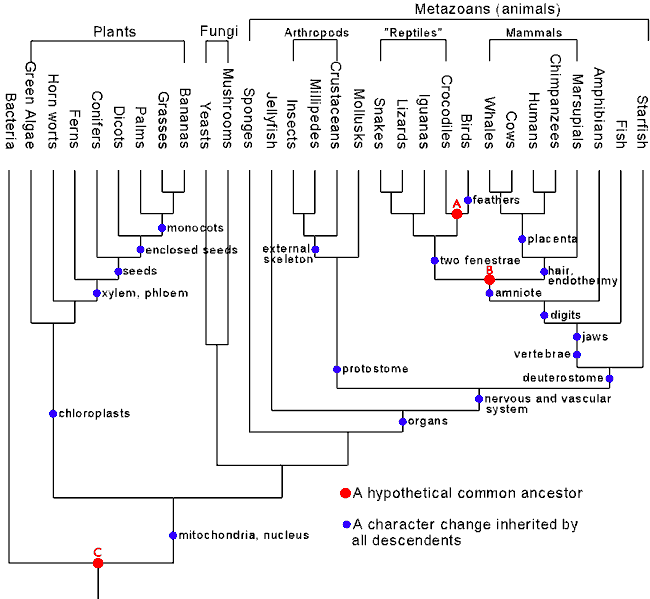 |
| Figure 1. The Consensus Phylogenetic Tree of All Life. |
The evidence from nuclear DNA alone is enough to confirm the reality of common descent. Things however become even more compelling when we look at the pattern of shared "errors, glitches, and mistakes" in the genome.
References
1. Tanaka, Y et al , "Construction of a human cytochrome c gene and its functional expression in Saccharomyces cerevisiae." J Biochem (Tokyo) (1988) 103: 954-61.
2. Clements, J. M. et al "Expression and activity of a gene encoding rat cytochrome c in the yeast Saccharomyces cerevisiae." Gene (1989) 83: 1-14.
3. Hickey, D. R. et al (1991) "Synthesis and expression of genes encoding tuna, pigeon, and horse cytochromes c in the yeast Saccharomyces cerevisiae." Gene (1991) 105: 73-81
4. Dobzhansky T "Nothing in Biology Makes Sense Except in the Light of Evolution" The American Biology Teacher (1973) 35:125-129
5. Watts J "Evolution or Creation? The argument from comparative anatomy." The Testimony January 2005 p 31-33
6. Tanaka, Y., Ashikari, T., Shibano, Y., Amachi, T., Yoshizumi, H., and Matsubara, H. (1988) "Construction of a human cytochrome c gene and its functional expression in Saccharomyces cerevisiae." J Biochem (Tokyo) 103: 954-61
7. Scarpulla, R. C., and Nye, S. H. "Functional expression of rat cytochrome c in Saccharomyces cerevisiae." Proc Natl Acad Sci (1986) 83: 6352-6
8. Dickerson, R. E., and Timkovich, R. cytochrome c. The Enzymes. (1975 P. D. Boyer. New York, Academic Press). 11: 397-547.
9. Yockey, H. P. (1992) Information Theory and Molecular Biology. (1992 Cambridge University Press) p 254
10. Theobald, Douglas L. "29+ Evidences for Macroevolution: The Scientific Case for Common Descent." The Talk.Origins Archive. Vers. 2.89. 2012. Web. 29 May 2014 <http://www.talkorigins.org/faqs/comdesc/> I am of course indebted to Theobald for many of the concepts in this article.


Comments
Post a Comment